Proxmox & HA: Praktijktest en conclusie

Een van de mooie features binnen een Proxmox cluster is het kunnen migreren van een VM/CT naar een andere node. Als een VM/CT gemigreerd wordt wat opgeslagen staat op een Ceph-cluster, hoeven er immers geen bestanden over te worden gezet en zijn het alleen de rekentaken en de inhoud van het RAM wat verplaatst moet worden.
Hieronder volgt een video van een VM waarin een Linux distributie wordt gemigreerd van Foxbox naar Oxbox. In de GUI van de VM ziet u een doorlopende ping inclusief timestamps naar de DNS-servers van Google. Tijdens deze taak wordt de migratie gestart in Proxmox. Wat opvalt is hoe snel de migratie gaat en dat de ping doorloopt met een minimale onderbreking.
Door middel van een script zou het migreren van een VM/CT geautomatiseerd worden als de CPU-load van een node te hoog wordt. Er dient wel rekening gehouden worden met de gereserveerde systeembronnen: Immers zijn niet alle nodes binnen de Proxmox-cluster even goed uitgerust om alle taken uit te voeren.
Het lijkt erop dat we alle gereedschappen nodig hebben om een virtuele machine of container op te zetten die door middel van Proxmox en Ceph, een hoge vorm van beschikbaarheid kan hebben.
Hieronder is het stappenplan om de praktijktest uit te voeren:
- Een lichtgewicht Debian container aanmaken
- Tijdens het aanmaken aangeven dat Arcephos gebruikt moet worden
- Een tekstbestand aanmaken op de container
- In proxmox aangeven dat de container als HA moet worden beschouwd
- De stroomstekker trekken van de node waar de container draait
De test is geslaagd als de container gestart wordt op een andere node en het unieke tekstbestand uit te lezen is. De configuratie van de container ziet er als volgt uit:
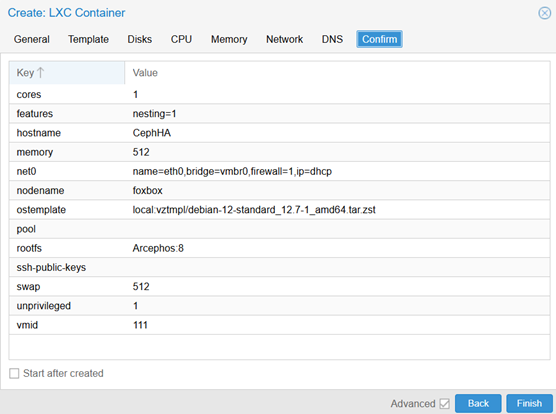
Na ingelogd te zijn in de container maak ik een bestand aan met daarin de tekst “Dit is een test.” Vervolgens geven we bij de Proxmox cluster aan dat de container CephHA als HA moet draaien.
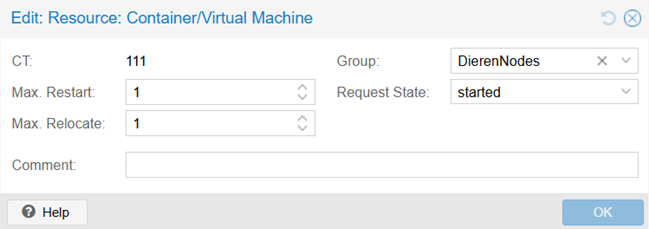
We hebben de optie om aan te geven hoe vaak de container maximaal opnieuw gestart mag worden en hoe vaak de node maximaal verplaatst mag worden. Verder kunnen we aangeven of de node gestart moet worden, uit moet blijven, of zijn laatst bekende staat moet aannemen. In het kader van een testopstelling laat ik alle instellingen op standaard. Ik heb voor deze test de groep DierenNodes aangemaakt. Door de container toe te wijzen aan deze groep, forceer ik dat als de node Foxbox offline gaat, Oxbox het stokje over moet nemen.
Hieronder volgt een filmpje van de praktijktest. Voel je vrij om vanaf 0:40 door te spoelen naar 2:30.
Conclusie en aanbevelingen
Zoals u kunt zien in hoofdstuk 4.8, valt de recovery time van de High Availability VM/CT met ruim twee minuten erg tegen. Dit is een scherp contrast als we de hersteltijd vergelijken met de tijd hoelang het duurt om een migratie uit te voeren, dit was namelijk secondewerk.
De reden dat de recovery van een HA zo lang duurt, heeft verschillende oorzaken. Proxmox heeft een tijdbuffer ingebouwd voordat het HA-proces gaat lopen. Dit is om te voorkomen dat tijdens een korte netwerkonderbreking gesleept gaat worden met allerlei HA VM/CT’s naar andere nodes.
Daarnaast speelt er nog een ander (optioneel) proces op de achtergrond bij het uitvallen van een node, genaamd Fencing. Dit proces zorgt ervoor dat de uitgevallen node zich niet meer mag aanmelden op het cluster. Vaak wordt dit geregeld door de computer uit te zetten door middel van out-of-band management of door op afstand de stroomvoorziening af te sluiten. Het doel van dit proces is om de ‘gezondheid’ van het cluster te waarborgen. Een praktisch geval zou kunnen zijn dat een ventilator van een node uitvalt. Hierdoor wordt de computer te warm en instabiel met als mogelijk effect dat hij een reboot krijgt. Tijdens deze reboot worden alle HA’s verplaatst naar andere nodes. Als de server met de falende ventilator zich nu weer aanmeldt bij het cluster terwijl fencing niet is ingeschakeld, begint het hele verhaal opnieuw.
Het advies is dan ook om technieken zoals Kubernetes te gebruiken voor redundantie en failback. Kubernetes is een stuk software wat op applicatieniveau zorgt dat bepaalde diensten blijven draaien op verschillende servers. Hoewel Kubernetes alleen maar CT’s kan beheren en geen ingebouwde persistent storage oplossing heeft, zou dat in combinatie met Ceph wel kunnen.
![rsyslog: remote logging en leren van fouten [2/2]](/content/images/size/w600/2026/02/Graylog-Log-Management-Software-2276774206.png)
![rsyslog: remote logging en hoe ik alles voor niets doe [1/2]](/content/images/size/w600/2026/02/1_2cL2-AQQuWAK9OolrEuXtA-3063350429.png)

