Proxmox & HA: Uitdagingen van een co-locatie

Inleiding
Ik ben twee jaar geleden gestopt met het gebruiken van “gratis” diensten die Cloud opslag bieden zoals Microsoft OneDrive, Google Drive of Dropbox. De reden hiervoor is dat het al snel heel erg duur wordt om grote hoeveelheden data op te slaan. De opslag is gratis tot en met vijf gigabyte voor OneDrive en vijftien gigabyte bij Google Drive. Vanaf daar wordt het al snel duur.

Wat veel goedkoper is, is om het zelf te hosten. Wat een hele goedkope oplossing is, is om zelf te hosten door ergens een Raspberry Pi in combinatie met een externe hardeschijf als opslagserver te gebruiken. Vooral de opkomst van goedkope SSD’s, kan op deze manier een redelijke fileserver opgezet worden voor een paar tientjes per jaar.
De Raspberry Pi is een fantastisch platform maar heeft echter ook zijn beperkingen. Wat de Pi energiezuinig maakt is ook meteen zijn beperking: Het is gebaseerd op ARM-architectuur en niet op x86. Daarnaast heeft de Pi weinig RAM en heeft het RAM-geheugen geen manier om met bit errors om te gaan. Virtualisatie op de Pi is haast niet te doen gezien de beperkte SoC.
Er zijn echter nog meer risico’s voor de bedrijfszekerheid van de Pi. Wat nou als de SSD het niet meer doet? En wat gebeurt er als het besturingssysteem vastloopt? Hoe gaan we verder als de stroom uitvalt? Hoe kan ik bij mijn bestanden komen die in de private cloud opgeslagen zijn, als de server geen internet heeft? De Raspberry Pi wordt dan al snel een Raspberry Pijn.
Dit verslag is een onderzoek naar de bovengenoemde risico’s en hoe we deze zorgen kunnen wegnemen of minimaliseren in een omgeving waar we niet alleen data willen opslaan, maar ook virtualisatie en containerisatie toepassen. De uitdaging ligt hier om continue bereikbaarheid van de diensten te hebben en dit zo goedkoop mogelijk te doen. Dit betekent dat er gebruik gemaakt gaat worden van gratis software, zwaar verouderde hardware dat gratis afgehaald kan worden en gratis stroom en internet van de vrienden, familie en buren welk me zo dierbaar zijn.
1.0: Distributed computing: De problemen
Het allermooiste zou zijn om alles wat thuis staat, te kopiëren en op een andere locatie neer te zetten. Op deze manier kan, zelfs als mijn huis afbrandt, het netwerk voortbestaan. Het probleem is dat dit economisch helaas niet haalbaar is. Los van het feit dat het geld me niet op de rug groeit zijn er allerlei technische problemen die aan het licht komen als de boel redundant wordt uitgevoerd. Laat u als lezer niet ontmoedigen door de problemen uit het volgende hoofdstuk. Technologie zou technologie niet zijn als het actuele problemen zou oplossen (en daarmee soms nieuwe problemen maakt.) Noodzaak is immers de drijfveer geweest voor een hoop ontwikkelingen die de mensheid heeft doorgaan. Vuur, het wiel, landbouw; allemaal dingen die ontstaan zijn uit een behoefte.
1.1: Een gespleten brein
Stel je voor dat op node A een bestand weggeschreven moet worden en op node B een bestand verwijderd moet worden. Terwijl dit gebeurt raakt de onderlinge communicatie kwijt. Hoe weet de cluster nou op welke node hij verder moet gaan? Beide nodes zullen denken dat ze de enige actieve node zijn waardoor gegevensconflicten kunnen bestaan.
Dit voorbeeld wordt een split-brain scenario genoemd en is een werkelijk probleem binnen geclusterde netwerken. De naamgeving van dit probleem stamt uit de neuropsychologie waar voor wat voor reden dan ook, de twee helften van de hersenen niet meer met elkaar kunnen communiceren.
Het effect hiervan is dat als een patiënt een afbeelding te zien krijgt in het gezichtsveld van de linkerhelft van het oog, de patiënt niet kan verwoorden wat hij gezien heeft omdat het spraakmechanisme van de hersenen aan de rechterkant zit.
Om het gespleten brein probleem te verhelpen, zou een derde speler een goede oplossing zijn; Een derde helft van het brein om het zo maar te noemen. Zo ontstaat er een situatie dat als een node offline gaat, er minder dan 50% van de cluster offline is. De derde node hoeft geen services te hosten of een hoop opslag te hebben, hij hoeft alleen maar in de gaten te houden wat de status is van de overige twee nodes.
Het mechanisme wat hiervoor een oplossing zou kunnen bieden heet quorum. Dit is een term uit de vergaderwereld en vertelt hoeveel leden aanwezig moet zijn bij een stemming om een geldige beslissing te nemen. Deze methodiek kunnen we prima toepassen op onze cluster.
3.2: Een enkele plek om gegevens op te slaan
Om synchronisatiefouten tegen te gaan hebben we idealiter een enkele plek om data op te slaan. Hierdoor hoeven beide nodes niet continu tegen elkaar te praten over hun datahuishouding. Er ontstaat een probleem als ineens de helft van de harde schijven wegvalt doordat een node offline is. Is de data dan nog steeds integer? Hoe bewijs je dat de data integer is? Hashing op bestandsniveau zou geen oplossing bieden omdat bij ontbrekende bestanden ook geen hashwaarde hebben. Hoe weet je hoeveel data je mist?
Het zou een nachtmerrie worden als we twee volumes met veel kleine bestanden continue synchroon moeten houden als de twee volumes geografisch uit elkaar liggen. Daarnaast loopt de uploadsnelheid van internetverbindingen bij consumenten sinds dag en jaar ver achter de downloadsnelheid. En hoe kunnen we zorgen dat de data nog steeds beschikbaar is als een node offline gaat?
Het probleem wat hierboven geschetst wordt, verschilt niet veel met harde schijven in een server bedoelt voor opslag. Er is in dat soort systemen redundantie ingebouwd door middel van RAID. Met deze techniek worden pariteit-bits opgeslagen op de harde schijven. De extra data kunnen gebruikt worden om ontbrekende data door middel van een kapotte harde schijf, te herstellen.
Zo eenzelfde redundantie kan ook opgezet worden op clusterniveau. De techniek die hiervoor wordt gebruikt heet Ceph. Ceph heeft een goede integratie met de hypervisor Proxmox die we gebruiken voor dit project en schaalt mooi als we in de toekomst meerdere nodes willen aanmaken. Met het gebruik van Ceph ontstaat er een virtuele harde schijf voor de nodes wat in werkelijkheid een gedistribueerde opslagmethode is.
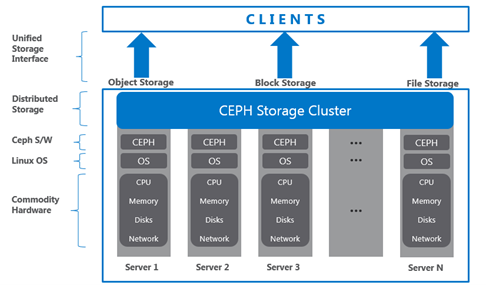
3.3: Onderlinge bandbreedte
Wat nou als de bandbreedte tussen de nodes zwaar onder de maat is? Dit klinkt als een recept voor synchronisatiefouten. Als ik een node opdracht geef om elke vier uur een back-up te maken, maar de dataoverdracht van de back-up duurt vijf uur, blijft er altijd achter net gevist worden want voor de volgende back-up heeft de node maar drie uur de tijd.
Zoals eerder is genoemd blijft de uploadsnelheid voor consumenten op een kabel- of xDSL verbinding ver achter. Dit heeft alles te maken met de beschikbaarheid van het aantal kanalen, het Data Over Cable Service Interface Specification (DOCSIS)-protocol en de behoefte van de consument. Er wordt nou eenmaal veel meer gedownload dan geüpload. In de ideale wereld heeft iedereen een synchrone gigabit verbinding. Helaas leven we niet in de ideale wereld en moeten er mitigerende maatregelen getroffen worden. Dat wil zeggen dat we de grootste bestandsoverdrachten, backups, zo klein mogelijk willen maken. Dit doen we door zo min mogelijk harde schijfruimte toe te wijzen aan de VM’s en containers, de frequentie van backups verlagen en snapshots gebruiken in plaats van complete kopieën.
3.4: Ongelijkwaardige hardware
Mocht er op node A een virtuele machine of container uitvallen, zou in het geval van een high-availability cluster, node B het moeten overpakken. Er kan zich een probleem voordoen als node B veel minder rekenkracht, bandbreedte of opslagruimte tot zijn beschikking heeft. Zo kan een taak met een Centrel Processing Unit (CPU)-load van slechts 20% op node A, een belasting van 80% zijn op node B en hiermee andere processen verstikken van rekenkracht. De cluster zal bestaan uit verschillende soorten hardware: een vroegere high-end Xeon CPU’s en een i3-processor van de negende generatie. Als een node offline gaat is de bedoeling dat de andere node het werk weer overneemt. Hoe gaan we hiermee om als er een groot verschil zit in de rekenkracht van beide machines?
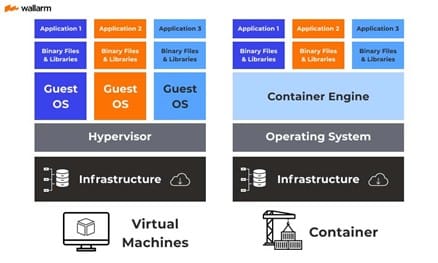
Momenteel worden een hoop services gehost door middel van virtuele machines. Door zoveel mogelijk diensten in een container te stoppen worden er een hoop systeembronnen vrijgemaakt. Dit komt doordat elke VM zijn eigen besturingssysteem moet inladen en zijn eigen RAM toegewezen krijgt. Bij containers werkt dit anders: Hier mag de userspace een beroep doen op de kernel van de host waar de container engine op draait. Daarmee vervangen we de zware OS-abstractie laag met de lichtere engine en komen meer systeembronnen vrij.
3.5: Fysieke bereikbaarheid van servers
Het kan wel eens gebeuren dat een computer vastloopt of een hardware-upgrade nodig heeft. Het zou zelfs kunnen dat na een reboot er op F1 gedrukt moet worden tijdens de Power On Self Test (POST) omdat de batterij die de Basic Input/Output System (BIOS)-instellingen bewaart leeg is en de computer niet meer weet hoe laat het is.
De strekking van het verhaal is dat het soms nodig is om op locatie te zijn om onderhoud aan een computer te doen. In het geval van een gedistribueerd computernetwerk kost dit extra veel tijd en moet het altijd in overleg met de eigenaar van het huis/pand. Een ander risico is dat een (kwaadwillende) gebruiker een van de nodes onbruikbaar maakt.
Er zal rekening moeten gehouden dat onderhoud aan de computers op afstand fysiek een stuk lastiger wordt. Ik wil vanwege veiligheidsmaatregelen de persoon waar het gehost wordt niet meer vragen dan of ze de stekker van de stroom er even uit en in willen doen. Als het besturingssysteem eenmaal is opgestart en een werkende internetverbinding heeft, kan ik in theorie alles via SSH doen. Het grootste risico voor onbereikbaarheid is dat als er iets misgaat met het bootproces. Er moet dus rekening gehouden worden met:
- Lege batterijen: voor deployment de spanning controleren.
- De “No keyboard detected, press F1 to continue.” Popup uitzetten in de BIOS.
- Stroomonderbreking: Als er weer spanning is moet de server automatisch opstarten.
- Vreemde flashdrives: de BIOS verplichten om van bekende hardware te booten.
- Kwaadwillende gebruikers: OS en BIOS voorzien van een sterk wachtwoord.
3.6: Netwerkbereikbaarheid van de servers
Het mooiste zou zijn als de cluster bereikbaar is vanaf een domeinnaam. Een statisch Internet Protocol (IP)-adres zou een mooie tweede zijn. Helaas zijn thuisnetwerken veelal voorzien van een IP-adres die niet gebonden is aan de modem. Dit wordt een dynamisch IP-adres genoemd en houdt in dat de modem van een internet service provider (ISP) een IP-adres kan leasen.
Een ander probleem is dat computers achter een modem/router van de internet provider zitten, achter een Network Address Translation (NAT)-firewall zitten. Dat houdt in dat verbinding vanuit het netwerk naar het internet makkelijk op te zetten zijn, maar andersom er wat configuratie nodig is. Immers: als een client via het internet aanklopt bij de modem/router, weet het apparaat niet met welk apparaat de client wil verbinden. Is het PC1, PC2 of toch de slimme wasmachine?
Dan is er nog een probleem: Wat als een client wil verbinden met de cluster via een domeinnaam, naar welk van de twee IP-adressen moet verwezen worden? Een Domain Name Service (DNS) A-record kan verwijzen naar slechts 1 IP-adres. Ik zou subdomeinen kunnen gebruiken zoals node1.cluster.com en node2.cluster.com maar dikwijls kan er maar een domeinnaam ingevuld worden in een app die met een van de twee clusters wil communiceren.
Het is omslachtig werk om op een computer de poorten open te zetten om te zorgen dat het verkeer goed gerouteerd wordt: De poorten van de service moeten gegoogeld worden, daarna inloggen op de modem/router, NAT regel aanmaken. Sommige mensen hebben nog een prive’ router staan terwijl de modem/router niet in bridge modus staat. Dit maakt een omslachtige klus al snel complex. Helemaal als dit voor elke node gedaan moet worden.
Wat al helemaal niet meehelpt is dat elke node een dynamisch publiek IP-adres heeft. Hoe stuur je een brief naar iemand die altijd aan het verhuizen is en niet vertelt waar hij nu woont?
Dynamic Domain Name Service (DDNS) zou hier een oplossing kunnen bieden: Elke node communiceert zijn dynamische, publieke IP-adres door aan een server. De server koppelt vervolgens het IP-adres aan een (sub)domeinnaam. Deze record wordt uiteindelijk gecommuniceerd naar de DNS-rootserver zodat iedereen in het wereldwijde web gebruik kan maken van het domein.
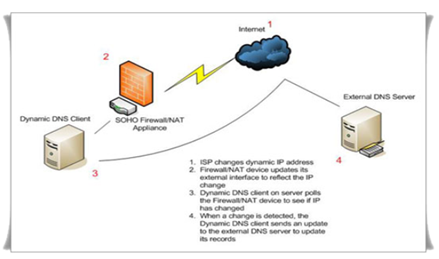
Een andere oplossing zou kunnen zijn om een eigen Virtual Private Network (VPN)-server te gebruiken de communicatie te laten verlopen via interne IP-adressen. Dit brengt echter een aantal nadelen met zich mee.
Als de VPN-server offline gaat voor wat voor reden dan ook, kunnen geen van de nodes met elkaar communiceren. Quorum kan niet meer toegepast worden waardoor de hele cluster van de leg kan gaan. Een ander nadeel is de extra overhead die ontstaat bij het gebruik van VPN. Eerder in dit verslag is aan bod gekomen dat internetverbindingen van consumenten een lage uploadsnelheid hebben. Om het meeste uit de bandbreedte te halen willen we zo min mogelijk overhead. Zelfs als we een VPN-verbinding opzetten zonder versleuteling opzetten is er sprake van overhead. Dit heeft alles te maken met het feit dat verstuurde informatie vanuit de client via de Transmission Control Protocol (TCP)/IP stack ingekapseld worden. Dit betekent dus dat er twee TCP-headers voorkomen in de uiteindelijke Ethernet frame.
Een laatste optie zou zijn om een extra server in dienst te nemen: deze server zou dan idealiter in een datacenter draaien, een synchrone gigabit verbinding hebben en een statisch IP-adres hebben. Zware specificaties hoeft de server niet te hebben: hij heeft alleen de taak om verkeer te routeren tussen de verschillende nodes in de cluster: een mediator als het ware. Het zou een single point of failure zijn, echter zijn datacenters zo opgesteld dat men mag verwachten dat daar gehoste servers altijd beschikbaar zijn. Het probleem is dat dit extra kosten met zich meebrengt en een extra host introduceert wat niet toevoegt aan het praktische nut van de cluster.
![rsyslog: remote logging en leren van fouten [2/2]](/content/images/size/w600/2026/02/Graylog-Log-Management-Software-2276774206.png)
![rsyslog: remote logging en hoe ik alles voor niets doe [1/2]](/content/images/size/w600/2026/02/1_2cL2-AQQuWAK9OolrEuXtA-3063350429.png)

